The Wonderful World of Computer Vision
Posted in Miscellaneous on Nov 25, 2015 by Umar Ahmed

Introduction
What do self-driving cars, Facebook, and security systems all have in common? Short answer...they all make use of the concepts of the field of computer vision. Computer vision and machine learning exist within the broad field of artificial intelligence, specifically related to the science of giving computers the ability to see.
![56574fa0dbf09515045907[1].jpg](/storage/app/uploads/public/565/7a7/411/5657a7411068c677588336.jpg)
The long answer to this question requires a much richer understanding of exactly what it means to see. When humans describe sight they are referring to much more than just receiving information from light. To see means to receive, interpret, and potentially respond to information in the form of light. Miraculously, humans are able to complete this process about five times per second taking millions of pictures throughout a lifetime using our eyes. However, computers don’t have eyes to see the world around them. Instead, they rely on digital cameras that convert light energy into electrical signals that a digital computer can understand. Computers can actually see a lot more than humans can. Humans are only able to see light within a fixed range within the visible spectrum of light. However, using more complicated sensors, computers can see infrared light, ultraviolet, they can see in slow motion, detect the smallest movements, and notice fine differences between colours that humans could never detect. In addition, computers do not suffer from the same problems that plague human vision such as optical illusions and motion blur. In many ways, computers have the potential to be superior to humans when it comes to sight, but they are limited only by the algorithms that define them.
How Computer Vision Works
The process through which computers see varies greatly depending on the application of the technology. However, the majority of the applications of computer vision follow a number of steps:
- Image Acquisition
- Image Processing
- Feature Extraction and Detection
- Decision-making.
Image Acquisition:
As mentioned before, computers cannot see the way that humans do. In order for a computer to receive light information and read it in a way that it can understand, a computer must make use of a digital camera which converts light into quantitative information. Cameras capture the red, green, and blue parts of the light of scene and send it to a computer as numerical data. Computers store this data in something called ‘pixels’ which form a two-dimensional array of light information, also known as an image. This new image is a collection of all the light data at one instance of a scene and can be used by a computer for various tasks.
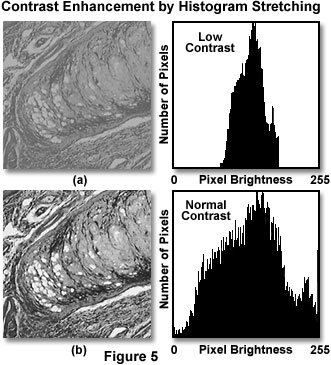
Image Processing:
Usually, an image requires a little bit of elbow grease before it can be used in any sort of computer vision computation. This often means that an image must be resampled in order to adhere to the correct color space, or that the amount of noise must be reduced, or features must be sharpened. Image processing can also take the form of adjusting the brightness, contrast, saturation, and exposure of an image so that the computer vision algorithms can more accurately detect features within the image.
Feature Extraction and Recognition:
This is the main stage in the computer vision process. In this stage a processed image is now analyzed using computer algorithms to detect features such as edges, lines, ridges, and shapes. These features and their attributes such colour, size, and orientation are compared with known features and classified into different categories.
Decision-making:
Once image features are recognized and categorized, decisions can be made by a computer. This usually entails a computer reacting to the recognized features and in the case of a self-driving car, telling the car to perhaps steer away from an oncoming obstacle. Or for example, a computer may identify a flaw in a manufactured product by recognizing mismatched features and would remove the defective product from the production line.
Areas Within Computer Vision
Computer vision describes a number of different sub-fields including:
- Object Recognition
- Image Manipulation
- 3D Reconstruction
- Motion Analysis.
Object Recognition:
This area of computer vision deals with identifying objects within images. This skill is quite difficult to achieve for a computer as objects in life do not always behave the same at all times. The goal of an object recognition algorithm is simple: identify an object in an image regardless of scale, orientation, visibility, and viewing conditions much the way that humans would be able to. Modern object recognition algorithms make use of very sophisticated levels of artificial intelligence and large databases of objects and their features in order train computers to recognize objects with a small margin of error. An example of the application of object recognition is face detection in Facebook. Facebook uses object recognition to detect faces within images, and it uses a database of faces to match your face to pictures of you.
Image Manipulation:
Image manipulation is when a computer alters the pixels of an image. This could be done to achieve some sort of image enhancement such as sharpening, contrast, noise reduction, or smoothing. Or a video sequence could be manipulated by stretching and distorting the image in order to smooth out the motion within the footage. Another application of image manipulation is image stitching. Image stitching involves combine multiple images together using common features to create a new image. Image stitching is commonly used in the film and video game industries, as well as in medical imaging and even for panoramic photography.
3D-Reconstruction:
This area of computer vision, also known as environment mapping, has to do with using images and motion to recreate three-dimensional environments. Computer algorithms utilize feature detection and principles such as parallax and shadows to create three-dimensional point-clouds of an environment. This point cloud can be used to create 3D computer geometry and stereoscopic images. This area of computer vision can also be used in the field of surveying and visualization in order to create measurements of a scene using images, also known as photogrammetry. A popular use of this area of computer vision is Microsoft's HyperLapse app.
Motion Analysis:
The analysis of the motion of objects in a sequence of images relies on the strength of accurate object recognition and motion estimation. Objects are tracked over a period of time for their translational motion, rotational motion, and change in scale in order to determine certain behaviours. Motion analysis is commonly used in the monitoring of vehicle traffic, the tracking of customers and pedestrians in stores and public places, surveillance, and robotics.
See a live demo of motion analysis in the browser.
Current and Future Trends
Significant progress has been made in the field of computer vision since the 1960s when development of the concept is believed to have begun. With the increase in computer processing, cheaper price of high-resolution cameras, and the rise in popularity of smartphones in the last decade, computer vision has been more powerful, cheaper, and more accessible than ever. Computer vision is used to today by companies like Google, Facebook, and Microsoft in areas such as facial recognition, autonomous vehicles, industrial quality control, surveillance and military intelligence. However, despite the recent developments in the field of computer vision, there are still some difficult problems to be solved and solutions to complete.
Challenges:
The problems with computer vision today have more to do with the issues of modern-day artificial intelligence than with the actual processing of images. Computer vision algorithms today require lots of resources to train in order to recognize objects with some degree of accuracy and consistency. In many ways, the capability of computers to see is at the same stage as an infant in its ability to recognize simple shapes and respond to movement. Computers have yet to learn how to make deep connections between what they see and the context of the situation.
Another possible problem with computer vision is the ethical concerns of giving computers sight. With more and more devices being given the ability to “see” the world at all times, the issue of privacy raises the ire of privacy experts and concerned individuals. How much should computers be able to see? Should companies be allowed to watch our movements and actions? These are all questions that are yet to be answered and will probably be answered very soon with the rise of the commercial applications of computer vision in our everyday lives.
The Future:
Besides the obvious prediction of faster CPUs and cheaper resources making computer vision more affordable and powerful, the future of computer vision lies in the advancement of artificial intelligence. With larger databases of information and better machine learning algorithms, computers may be able to improve object recognition and motion estimation greatly. Engineers and scientists predict that within the next 20 years, improvements in the field of artificial intelligence will give rise to the next generation of autonomous robots. These robots will be able to use the advancements in computer vision to interpret and react to sudden dangers in their path in near real-time and warn other robots and humans of the same obstacle.
Conclusion
Despite great developments in the past few decades, the field of computer vision still has a long way to go. However, every day scientists and engineers are getting one step closer to the goal of giving computers the capability of “seeing” the way that humans do.
Works Cited
Szeliski, Richard. 2010. "Computer Vision: Algorithms and Applications." Szeliski.org. September 3. Accessed November 25, 2015. http://szeliski.org/Book/drafts/SzeliskiBook_20100903_draft.pdf.
2013. Dynamic target tracking camera system keeps its eye on the ball #DigInfo. Directed by DigInfo TV. Performed by University of Tokyo. https://www.youtube.com/watch?v=qn5YQVvW-hQ.